- Published on
How does Github store millions of repo and billions of files?
Github is one of the world’s largest code hosting platforms for collaboration and version control.
Scale at Github
Repository - 200M Repo (Including 30M Public Repo)
Active Users - 50M
Before directly jumping into data storage, let’s quickly go through Github Architecture once.
Github Architecture
Whenever you type a Github repo URL in the browser, a lot of things happen behind the scene to show you a beautiful repo page.
Here is the quick flow -
- Suppose, you type https://github.com/github/docs in the browser.
- After all the fancy DNS stuff, request comes to the Github load balancer
- Load balancer forwards the requests to one of front end server ( typically 8 Core CPU, 16 GB RAM Bare Metal Server)
- Nginx (reverse proxy server) at frontend server ships the request to Unix Domain Socket (16 Unicorn worker processes are running on it)
- One of the workers, grabs it and sends it to backend (Running on Ruby on Rails) Backend has connection with MySQL and cache
- If cache miss, Github uses the Grit library to retrieve the data.
- Grit makes RPC call (Remote procedure call) to Smoke Service (It has direct access to filesystem & mapped to frontend machines)
- Frontend machines run 4 proxy machine instance
- Proxy extracts the username of repo from request
- Then Chimney (A library which gives route to Smoke service) talks to Redis for route and gives back to Smoke
- Smoke establishes a transparent proxy with proper file server
- The response is sent back through smoke proxy to Ruby on rails app
- It sends back response to client via Nginx (not through load balancer)
Slave file servers keeps memcache server.
IMPORTANT - Github uses Rackspace instead of Amazon EC2 as Amazon Elastic Block Store was not nearly as fast as bare metal when they ran benchmarks for handling high disk IO operations.
Old Github File Storage
Initially Github used GFS (Global File System) but as they grew, scalability took a hit. After connecting more servers to the file system, performance degraded rapidly.
For MySQL database replication they were using DRBD (Database Replicated Block Device) which is a distributed, flexible and versatile replicated storage solution for Linux.
New Github Storage
In the new architecture, Github removed the shared file system completely and started using federated storage (a collection of autonomous storage resources which are being monitored by a common management system that provides rules, how data is stored, managed and migrated throughout the storage network).
In the new system, they could add as many additional machines (Linux machines running ext3/ext4) they wanted, without hitting the performance.
Spokes
Github has developed a very nice system called “Spokes” (previously known as D-Git) to store multiple distributed copies of a github repo across data centres.
Spokes stores multiple replicas of a repo and keeps all replicas in sync. It does replication at Git application level, replacing the older system that did replication at the file system block level.
GitHub makes use of the three-phase commit protocol in order to update replicas, and also a distributed lock to ensure the correct update order
How data is stored in file storage?
All data in a Git repo is stored in a Direct Acyclic Graph. Every commit has a link with it’s parent commit. It also has a link to a tree which keeps a snapshot of the working directory in the moment when the commit was created. This tree links to the sub-tree (folders & files) and sub-trees recursively links to other sub-trees.
Every object in this highly dense tree, is indexed in the database by SHA-1 hash of their content.
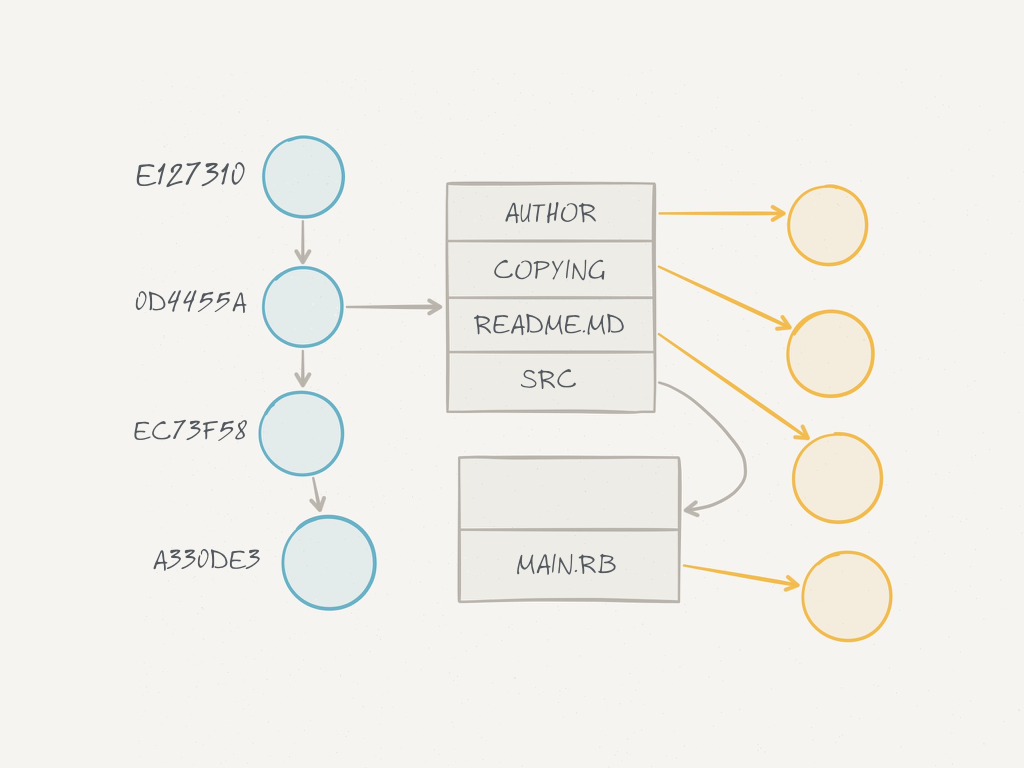
Spokes system uses Git’s property and stores 3 copies of each Github repo on 3 different servers. In the worst case, even if two servers are down, one server would still be available for read, clone and pull.
For each push to a Git repo, it goes through a proxy which is responsible for replicating the change.
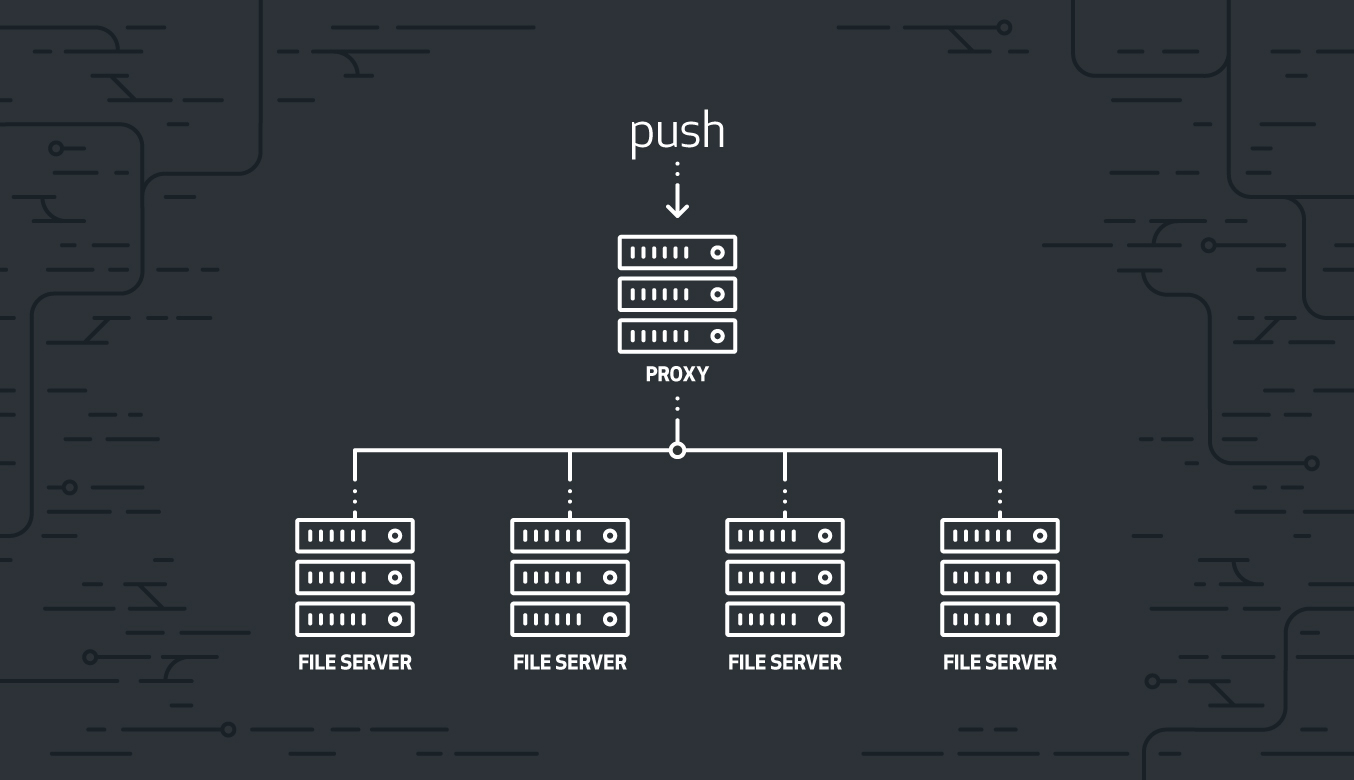
Github Spokes’s design, with optimization of the performance of distributed reference updates, now allows Spokes to replicate Git repositories effectively. This improves robustness, speed, and flexibility.