- Published on
The basics you need to know about Kafka [Graphic Explanation Ahead 🖥️]
Hey 👋
Welcome to my Apache Kafka series. In this series, we will be, one by one covering, (with the help of interactive & friendly graphics) from the basic terminology to deep diving into the brilliant architecture behind the wonderful piece of software, Kafka.
What is Kafka?
Kafka is a distributed event streaming platform which is designed to be fast & scalable.
OK, so what is event streaming?
Basically, an event is like “something happened” in the world.
For example - Pankaj paid $100 to Ashish. So, this is an event which happened in our system.
In today’s world where we have a lot of real time data (which is streams of events) coming in every second to our system. So, to handle & store such a large amount of data effectively for later retrieval to process it, Kafka was introduced.
The main aim behind the Kafka is to provide a high-throughput (data processed in a given time frame) & low latency (time taken by the service to respond) platform to handle real time data.
A rough idea on how it works?
Sure! On a high level it works like a publisher-subscriber model.
Just think of subscribing to a newsletter. You subscribe to the newsletter and you receive a post whenever the author publishes.
The same way Kafka works, two backed services talking to each other via Kafka. One is a producer, who pushes data to a topic (newsletter) on Kafka and on the other side, there is a consumer who subscribes to that topic and reads the content, Simple right!
What’s producer and consumer now?
Producer and consumer are the backend services which respectively send and read messages from kafka.

BUT we will have to organise data based on different types of categories. That’s why Kafka has a concept called -
Topics
As the name suggests, topics are basically addresses in kafka, to which a message is sent by the producer. Consumers can listen to this topic and read data.
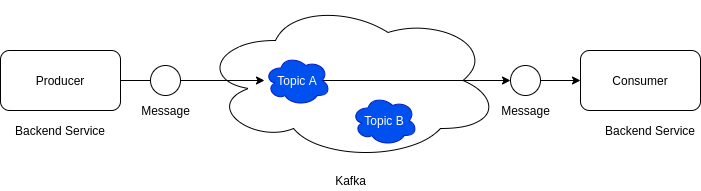
Things to Note
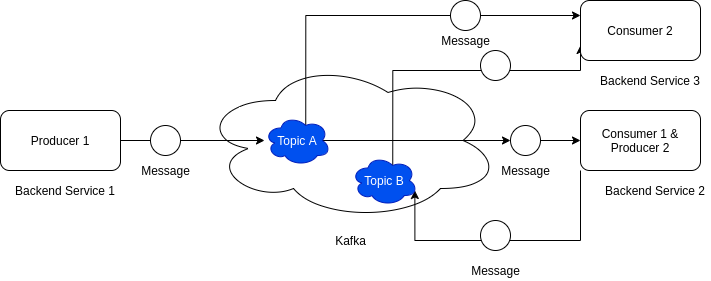
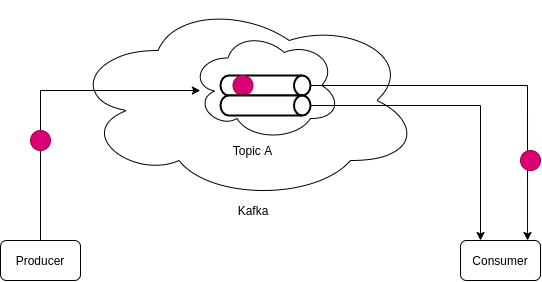
- The same service can behave like both a producer and a consumer (see service 2 below).
- There can be multiple consumers fetching the same data from kafka. (consumer 1 & 2 reading from Topic A)
- A service can listen to as many topics it wants (consumer 2)
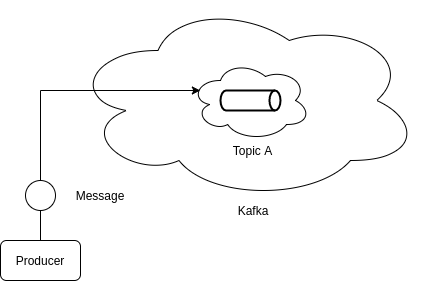
Interesting… So how data is stored?
A topic behaves like a pipe. Producer keeps on pushing data to it, and on the other side the consumer reads it.
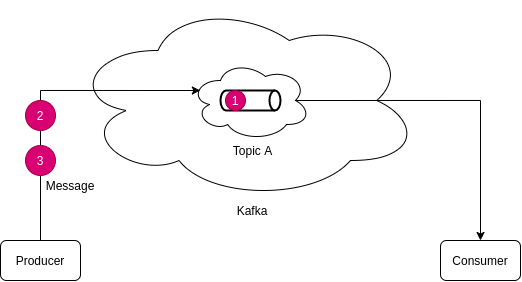
Let’s visualise, for example a message is sent to some topic A -
So, Messages are stored in the pipe, permanently. Messages stay in the pipe always and can not be modified or deleted.
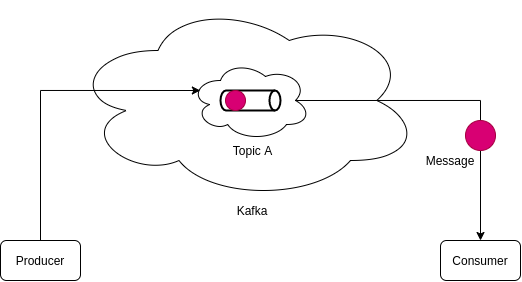
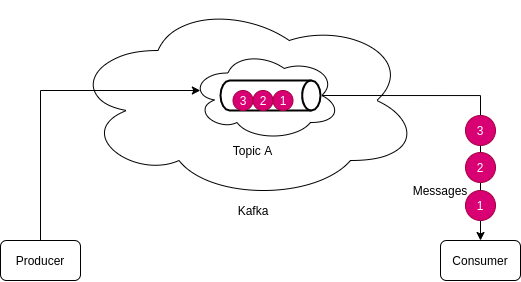
Let’s send some more messages.
Consumers get these messages in the same order.
The same thing happens with every topic in the Kafka cluster (don’t worry, we will discuss what Kafka cluster is).
P.S.
- These messages are stored permanently in kafka, They can not be modified or deleted but any way we can set in kafka configurations to auto delete data after a period of time.
- Kafka guarantees the correctness of the messages.
BONUS TIP : You might think that Kafka would be using queue data structure internally. It’s not true. Kafka uses a “log” data structure. It is a persistent data structure which allows only appends, no editing, no deletion. In detail, we will cover this some other day.
So, these Kafka topics allow us to store data asynchronously irrespective of whether the consumer or producer goes down.
Partitions
Ok, I have a confession 😟. I lied. A Kafka topic is not just a single pipe. It’s a combination of pipes which helps kafka scale. Every pipe is called partition.
So, any message published to kafka would go to any of the partitions. We can configure the topic also otherwise the kafka topic would do it in it’s own way using some fancy algo as round robin.

Consumers get the messages in the same order they were pushed. This explanation clears out a very important concept -
For a consumer, messages coming from a partition would always be in order but ordering of messages coming from a topic is not guaranteed. Read it again.
NOTE : Every message, pushed to a kafka topic will have a sequence ID which is called offset.
Kafka Cluster
Simply, a kafka cluster is a group of machines (for example AWS EC2) running kafka on it. It makes its nature distributed.
So, who manages all machines? Here, the Kafka zookeeper comes into the picture.
Zookeeper
Zookeeper is the brain of a kafka cluster. It sits on the top of it and manages metadata of all the topics & partitions in all machines (let’s call these machines, nodes). These machines are known as brokers also.
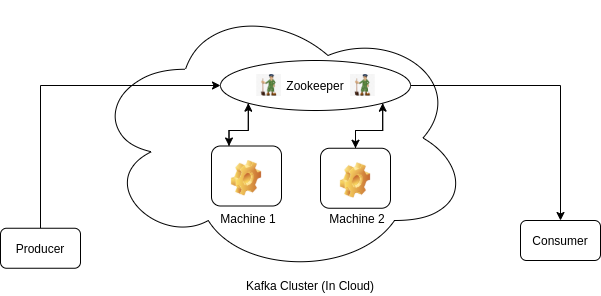
Topic’s partitions are distributed across all the nodes (machines) available in the cluster.
Zookeeper’s leader-follower concept
Zookeeper follows a leader-follower concept. For any topic, it assigns a node as leader and rest as follower.
Let’s say, topic A has partition #1 which is distributed across all nodes. Whenever a new message comes to the topic A, Zookeeper will give it to the leader, it will give the message to the leader node and asynchronously leader node will give write request to all the follower nodes. In the same way, consumer will read message from partition leader. (if any)
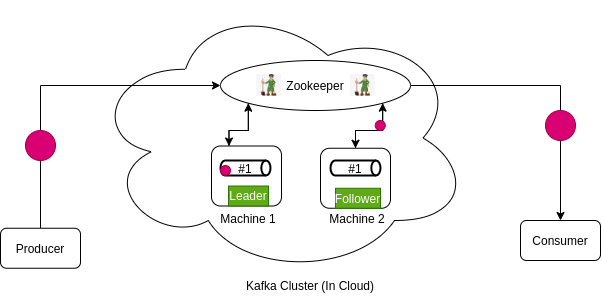
Followers nodes are super lazy!! They do nothing. They just store the exact copy of data & relax. Poor leader node, handles all the dirty work of reading and writing.
Whenever the leader goes down, A new leader is assigned from any of the follower nodes and the same process goes again.
The same thing will happen for each partition.
Zookeeper basically stores meta data (such as location) of all topics and partitions. Recently, In kafka v2.8.0, zookeeper dependency was removed. It would be interesting to see the new architectural implementation without a zookeeper. We will cover it in future posts.
I hope, now you have a fair understanding of what kafka is and how it functions. It was like a cheat sheet to understand kafka. In the next posts of this series, we will deep dive and discuss each and every tiny part of kafka in detail.